
I’ve had to solve an interesting problem this week. I started the week with an SSIS package that ran in 2 minutes. It extracts a million transaction records from DB2 to a file, uploads the file to Azure Blob Storage and BULK IMPORT’s the file into an Azure SQL Database staging table. All in 2 minutes. This was acceptable performance and faster than any of the other options we were considering.
Each of the DB2 records represents an Insert, Update or Delete to the base table in DB2. I get the Transaction Type (M – Merge (Insert/Update) or D – Delete), and a time stamp in addition to the columns from the row.
So a typical set of rows might look like this:
| Id (Identity) | Field1 | Field2 | Field3 | Field4 | TrxType | RowCreatedTimeStamp |
| 1 | 13940001 | 1 | 24785779 | 41 | M | 11:37:31.650 |
| 2 | 13940001 | 2 | 24785779 | 20 | M | 11:37:32.070 |
| 3 | 13940001 | 3 | 24785779 | 26 | M | 11:37:32.185 |
| 4 | 13940001 | 2 | 24785779 | 21 | M | 11:37:32.205 |
| 5 | 13940001 | 3 | 24785779 | 4 | M | 11:37:32.265 |
| 6 | 13940001 | 2 | 24785779 | 29 | D | 11:37:32.391 |
| 7 | 13940001 | 2 | 24785779 | 18 | M | 11:37:33.392 |
In the example above, the rows are all for the same document (See Field1: value 13940001). Rows with Field2= 1, 2, 3 were added. Then row 2 and 3 were changed (Id 4, 5). Then row 2 was deleted (Id 6) and a new row 2 was inserted (Id 7).
Here is the definition of the source table in the Azure SQL Database:
CREATE TABLE ETLSource(
Field1 [numeric](12, 0) NULL,
Field2 [smallint] NULL,
Field3 [int] NULL,
Field4 [smallint] NULL,
Field5 [nvarchar](1) NULL,
[UpdateType] [nchar](1) NOT NULL,
[RowCreated] [datetime2](7) NOT NULL,
[Id] BIGINT IDENTITY NOT NULL
) WITH (DATA_COMPRESSION = PAGE)
GO
CREATE UNIQUE CLUSTERED INDEX ETLSourcePK ON ETLSource (Id) WITH (DATA_COMPRESSION = PAGE);
CREATE UNIQUE NONCLUSTERED INDEX ETLSourceIdx1 ON ETLSource (UpdateType, RowCreated, Field1, Field2) WITH (DATA_COMPRESSION = PAGE);
CREATE UNIQUE NONCLUSTERED INDEX ETLSourceIdx2 ON ETLSource (Field1, Field2, UpdateType, RowCreated) WITH (DATA_COMPRESSION = PAGE);
GO
And here is the definition of the target table in the Azure SQL Database:
CREATE TABLE ETLTarget(
Field1 [numeric](12, 0) NULL,
Field2 [smallint] NULL,
Field3 [int] NULL,
Field4 [smallint] NULL,
Field5 [nvarchar](1) NULL,
[BatchDate] [datetime2](7) NULL
) WITH (DATA_COMPRESSION = PAGE)
GO
CREATE CLUSTERED INDEX ETLTargetPK ON ETLTarget (Field1, Field2) WITH (DATA_COMPRESSION = PAGE);
GO
At first, I tried a cursor. I know how to write them and it was easy enough to create a cursor that looped through the rows and used either a DELETE statement or a MERGE statement to deal with each one. Here’s what that looked like:
DECLARE @BatchDate DATETIME2(7) = SYSUTCDATETIME();
DECLARE @Field1 NUMERIC(12, 0)
DECLARE @Field2 SMALLINT
DECLARE @Field3 INT
DECLARE @Field4 SMALLINT
DECLARE @Field5 NVARCHAR(1)
DECLARE @UpdateType CHAR(1)
DECLARE @RowCreated DATETIME2(7)
DECLARE cur CURSOR LOCAL FAST_FORWARD FOR SELECT
Field1
,Field2
,Field3
,Field4
,Field5
,UpdateType
,RowCreated
FROM ETLSource
ORDER BY id
OPEN cur
FETCH NEXT FROM cur INTO
@Field1
, @Field2
, @Field3
, @Field4
, @Field5
, @UpdateType
, @RowCreated
WHILE @@fetch_status = 0
BEGIN
IF @UpdateType = 'D'
BEGIN
DELETE FROM dbo.ETLTarget
WHERE Field1 = @Field1
AND Field2 = @Field2;
END
IF @UpdateType = 'M'
BEGIN
--Merge the changes that are left
MERGE ETLTarget AS target
USING (
VALUES(
@Field1
, @Field2
, @Field3
, @Field4
, @Field5
)
) AS source (
Field1
, Field2
, Field3
, Field4
, Field5 )
ON (target.Field1 = source.Field1
AND target.Field2 = source.Field2)
WHEN MATCHED
THEN UPDATE
SET target.Field3 = source.Field3
,target.Field4 = source.Field4
,target.Field5 = source.Field5
,target.BatchDate = @BatchDate
WHEN NOT MATCHED BY target
THEN INSERT (
Field1
, Field2
, Field3
, Field4
, Field5
, BatchDate)
VALUES (@Field1
, @Field2
, @Field3
, @Field4
, @Field5
, @BatchDate);
END;
FETCH NEXT FROM cur INTO
@Field1
, @Field2
, @Field3
, @Field4
, @Field5
, @UpdateType
, @RowCreated
END
CLOSE cur
DEALLOCATE cur
Unfortunately, this solution was TERRIBLY slow. Cursors are notorious for being slow. This one worked fine for 1,000 transaction rows, but, after running for an hour and only processing a small portion of the million rows, I killed it and went looking for a set-based alternative.
Next, I tried a set-based MERGE statement. This was problematic because it kept complaining that multiple source records were trying to change the same target record. This complaint made sense when I realized that a row might be inserted and updated in the same day so it would have two source transactions. So I needed to get rid of the extras. It turns out that I really only care about the latest change. If it’s an insert or update, MERGE will insert or update the target row appropriately, if it’s a delete, MERGE can handle that too. But, how to select only the most recent row for each key? The standard de-duplication CTE query served as a model. Here is the final statement that worked:
WITH sourceRows AS (
SELECT *, RN = ROW_NUMBER() OVER (PARTITION BY
Field1, Field2
ORDER BY Field1, Field2, RowCreated DESC)
FROM ETLSourceStagingTable)
INSERT INTO ETLSource (
Field1
, Field2
, Field3
, Field4
, Field5
, UpdateType
, RowCreated)
SELECT
Field1
, Field2
, Field3
, Field4
, Field5
, UpdateType
, RowCreated
FROM sourceRows
WHERE RN = 1
ORDER BY RowCreated;
Note the introduction of a Staging Table. The SSIS package now uses BULK INSERT to load the Staging Table from the file in Blob Storage. The query above is used to load only the relevant rows (the most recent) into the ETLSource table. The Staging Table has the same structure as the ETLSource table, without the Id column. And has an index on it like this:
CREATE INDEX ETLSourceStagingTableSort ON ETLSourceStagingTable
(Field1, Field2, RowCreated DESC) WITH (DATA_COMPRESSION = PAGE)
The use of the Staging Table and the CTE query above meant that of my original 7 rows in the example above, only three are relevant:
| Id (Identity) | Field1 | Sequence | Field3 | Field4 | TrxType | RowCreatedTimeStamp | Relevant |
| 1 | 13940001 | 1 | 24785779 | 41 | M | 11:37:31.650 | YES |
| 2 | 13940001 | 2 | 24785779 | 20 | M | 11:37:32.070 | |
| 3 | 13940001 | 3 | 24785779 | 26 | M | 11:37:32.185 | |
| 4 | 13940001 | 2 | 24785779 | 21 | M | 11:37:32.205 | |
| 5 | 13940001 | 3 | 24785779 | 4 | M | 11:37:32.265 | YES |
| 6 | 13940001 | 2 | 24785779 | 29 | D | 11:37:32.391 | |
| 7 | 13940001 | 2 | 24785779 | 18 | M | 11:37:33.392 | YES |
Now, I just needed to craft the MERGE statement properly to work. When I did, this is what I had:
MERGE ETLTarget AS target USING (
SELECT
Field1
, Field2
, Field3
, Field4
, Field5
, UpdateType
FROM ETLSource
) AS source (Field1
, Field2
, Field3
, Field4
, Field5
, UpdateType)
ON (target.Field1 = source.Field1
AND target.Field2 = source.Field2)
WHEN MATCHED AND source.UpdateType = 'M'
THEN UPDATE
SET target.Field3 = source.Field3
,target.Field4 = source.Field4
,target.Field5 = source.Field5
,target.BatchDate = @BatchDate
WHEN MATCHED AND source.UpdateType = 'D'
THEN DELETE
WHEN NOT MATCHED BY TARGET AND source.UpdateType = 'M'
THEN INSERT (Field1
, Field2
, Field3
, Field4
, Field5
, BatchDate)
VALUES (Field1
, Field2
, Field3
, Field4
, Field5
, @BatchDate);
Which was fine for a small data set, but crawled on a big one, so I added batching so the merge only had to deal with a small set of rows at once. Since the clustered PK is an identity column, and since I truncate ETLSource before loading it, I am guaranteed that the Id column will be values 1…n where n is the total number of rows. So, I initialize an @rows variable right after inserting the rows into ETLSource:
SET @rows = @@rowcount;
Next, I create a while loop for each batch:
DECLARE @batchSize INT = 10000;
DECLARE @start INT = 1;
DECLARE @end INT = @batchSize;
WHILE (@start < @rows)
BEGIN
MERGE ETLTarget AS target USING (
...;
SET @start = @start + @batchSize;
SET @end = @end + @batchSize;
END
Then I add the @start and @end to the MERGE statement source:
MERGE ETLTarget AS target USING (
SELECT
Field1
, Field2
, Field3
, Field4
, Field5
, UpdateType
FROM ETLSource
WHERE id BETWEEN @start AND @end
) AS source
And this worked!!! I was able to process a million rows in 1 minute. Yay!
Then I tried 10 million rows. Ugh. Now the MERGE was only processing 10,000 rows per minute. Crap. What changed? Same code. Same data, just more of it. A look at the query plan explained it all. Here it is with 1 million rows:

And here it is with 10 million rows:
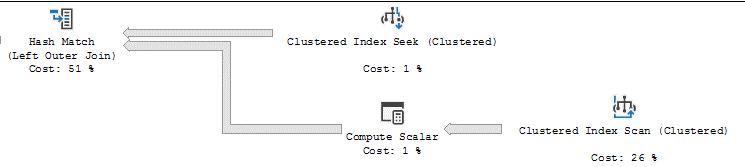
The ETLTarget table has 80 million rows in it. When I had 10 million rows in the ETLSource table, the query optimizer decided that it would be easier to do an Index SCAN instead of a SEEK. In this case, however, the SEEK would have been A LOT faster.
So how do we force it to use a Seek? It turns out the optimizer has no idea how many rows were processing in a batch, so it bases its optimization on the entire table. We could use the Loop Join hint a the end of the merge statement:
MERGE ... , @BatchDate)
OPTION (LOOP JOIN);
But most folks like to avoid these kinds of hints. So we needed another way. Someone suggested putting in a TOP clause in the Source SELECT statement. That worked. Here’s how the MERGE looks now:
MERGE ETLTarget AS target USING (
SELECT TOP 10000
Field1
, Field2
, Field3
, Field4
, Field5
, UpdateType
FROM ETLSource
WHERE id BETWEEN @start AND @end
ORDER BY id
) AS source
With this in place, I was able to process the 10 million rows in 10 minutes. Woohoo! Just to be sure, I re-ran the process with a thousand, a million and 10 million rows and it was consistent. I was able to process a million rows a minute.
